
《冰山不止一角,Iceberg 與 S3》系列已對 Trino 搭配 Iceberg on S3 做了較為全面的介紹,說明這組「黃金組合」的優缺點,並分享筆者對成本與效能優化的一些實際嘗試。
《為什麼我改用 Iceberg》系列中,筆者將進一步分享公司當初是從哪些角度出發、有何起心動念,才決定將原本廣受好評的 Google BigQuery 替換為 Trino + Iceberg on S3。
此外,也會補充尚未介紹的兩大 Iceberg 賣點:基模演進(Schema Evolution) 與 增量查詢 (Incremental Read)。
首先要說明 BigQuery 在筆者公司的應用場景,除了導入分析倉儲之批次 ELT 排程,公司的資料分析師及部分有分析權限的 PM 都會使用 BigQuery 來進行資料分析及內部分析報表製作。
這使得要有充足的理由才能讓同仁有動力做分析的平台轉換,適逢筆者公司在做財務調整,政策上偏向對成本做節流,恰巧此架構在儲存成本上有優勢,於是筆者就針對成本以及基本的效能分別做了比較實驗:
首先,將 BigQuery(prod) 自 2024-01-01 以後之 total_slot_ms,依每天 24 小時對 total_slot_ms 做聚合,分別算出每小時排程工作需使用之 total_slot_ms 的 min max avg 值:
-- Calculate BQ Usage by hour
SELECT
FORMAT_TIMESTAMP('%H', creation_time_hr) AS creation_hour,
MAX(total_slot_ms_hr) AS max_total_slot_ms,
MIN(total_slot_ms_hr) AS min_total_slot_ms,
AVG(total_slot_ms_hr) AS avg_total_slot_ms
FROM(
SELECT
TIMESTAMP_TRUNC(creation_time, HOUR) AS creation_time_hr,
SUM(job.total_slot_ms) AS total_slot_ms_hr
FROM
`region-us`.INFORMATION_SCHEMA.JOBS AS job
WHERE
-- 限定 production 環境的 project
project_id = 'xxxxx-xxxxxx'
AND statement_type != 'SCRIPT'
AND DATE(creation_time) >= '2024-01-01'
GROUP BY creation_time_hr
)
GROUP BY creation_hour
ORDER BY creation_hour ASC;
total_slot_ms 換算成 *一小時 內跑完所需的 slot 數量,依照 min max avg 值分別計算 (右邊淡黃三欄):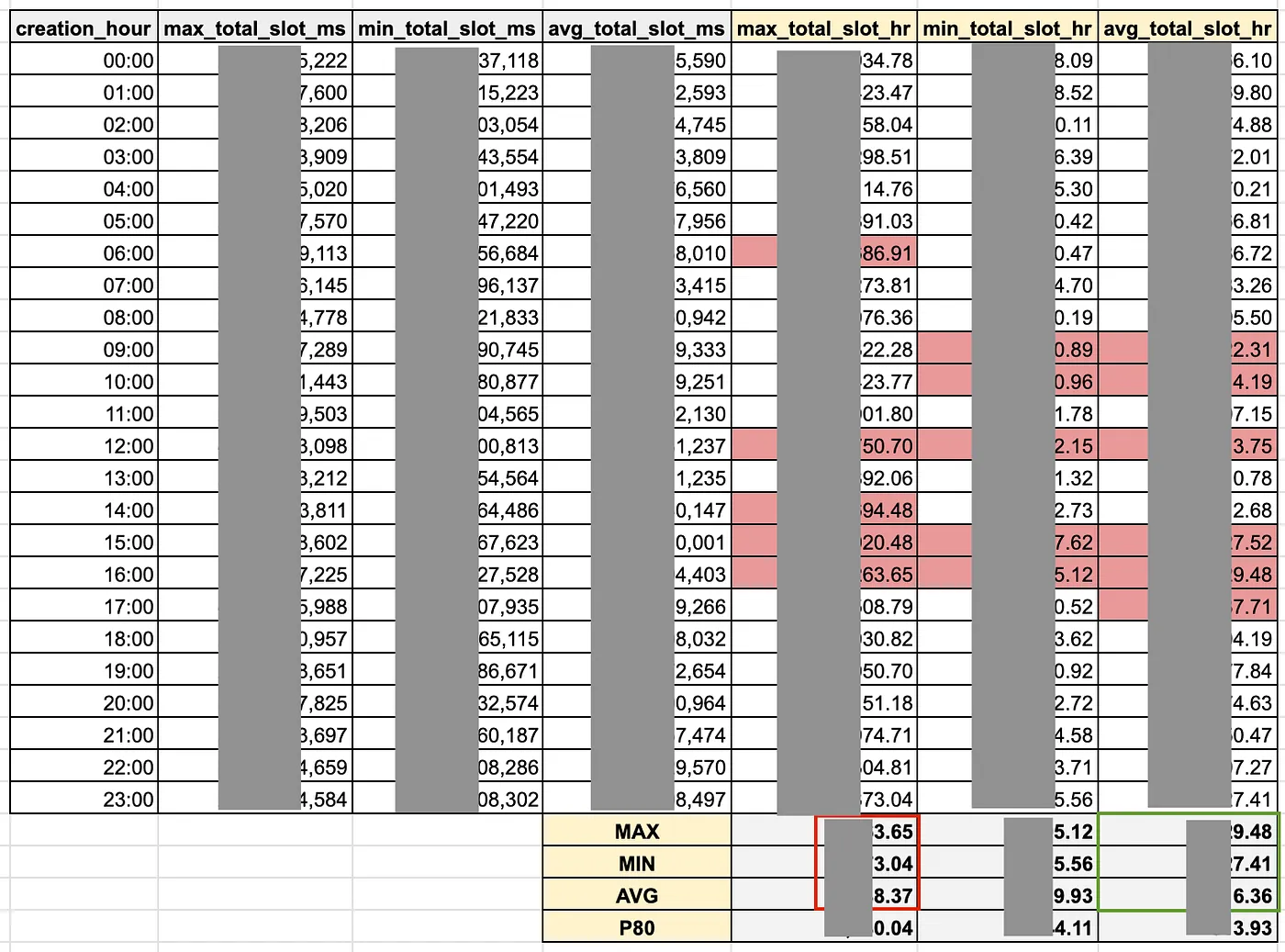
*一小時 實際上是 45分鐘:
筆者公司的 hourly batch job 通常要求要 45 分鐘內執行完畢,避免影響下個小時的排程。
EC2 c8g.2xlarge (8c16g) 的訂價估算同等機器 ( 以 cpu 數量估算 ) 一個月需花多少錢,以此估計搬遷至 Trino 的機器成本,其中:max_total_slot_hr 的上下界來估算 )avg_total_slot_hr 的上下界來估算 )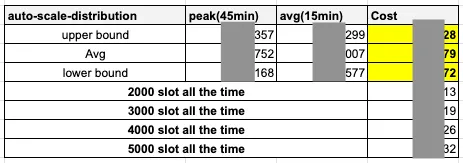
系列文明日《為什麼我改用 Iceberg (二)》將接續今日,繼續講述未完的基本效能實驗,並總結比較結果以及改用 Iceberg 決策關鍵。
My Linkedin: https://www.linkedin.com/in/benny0624/
My Medium: https://hndsmhsu.medium.com/

